
ETL Process Optimization: A Practical Guide to Faster, Cheaper Data Pipelines
Every data team eventually hits the same wall. The nightly pipeline that once finished in an hour now runs for five, dashboards load stale numbers, and cloud bills creep upward every month. The cause is almost always the same: a pipeline built to simply work, never tuned to work well. ETL process optimization is how you fix that, turning a slow, expensive, fragile pipeline into one that runs fast, costs less, and rarely breaks.
This guide walks through the practical side of the problem. It covers how to find what is actually slowing you down, the techniques that deliver the biggest gains across extraction, transformation, and loading, and the habits that keep a pipeline healthy as your data grows. The goal is not theoretical perfection but real, measurable improvement you can apply to the pipelines you already run.
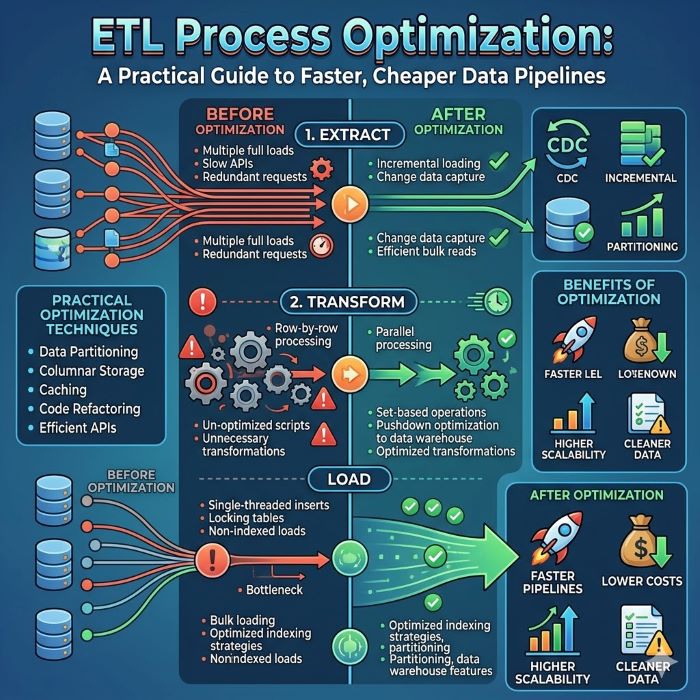
What ETL Optimization Really Means
ETL stands for Extract, Transform, Load, the three stages of moving data from source systems into a destination like a data warehouse. Extraction pulls data from databases, files, and APIs. Transformation cleans, reshapes, and enriches it. Loading writes the result into the target. A pipeline strings these stages together, often running on a schedule.
ETL process optimization is the work of making that pipeline faster, cheaper, and more reliable without changing what it ultimately produces. It is about removing waste, eliminating bottlenecks, and using your compute and storage more efficiently. A well-optimized pipeline delivers fresh data sooner, survives spikes in volume, and keeps costs predictable.
The reason this matters more every year is data growth. A pipeline that handled a million rows comfortably can choke on a hundred million, and the inefficiencies that were invisible at small scale become expensive at large scale. Good optimization is what lets a pipeline grow with your business instead of becoming the thing that holds it back.
Start by Finding the Bottleneck
The most common optimization mistake is guessing. Teams rewrite a transformation they assume is slow, only to find the real delay was in extraction the whole time. Effective ETL process optimization always begins with measurement, not assumptions.
Start by timing each stage of the pipeline separately. Measure how long extraction, transformation, and loading each take, and you will almost always find that one stage dominates the total runtime. That stage is where your effort belongs, since speeding up a step that takes two percent of the runtime is wasted work. This is the classic principle of focusing on the bottleneck rather than spreading effort evenly.
Look for the usual suspects at each stage. Extraction is often slowed by pulling far more data than needed or by hammering a source system with inefficient queries. Transformation bottlenecks usually come from row-by-row processing, poorly written joins, or doing work in the wrong place. Loading slows down when writing huge volumes inefficiently or fighting with indexes and constraints on the target. Profiling tools, query execution plans, and pipeline logs all help you pinpoint exactly where time goes. Once you know the true bottleneck, the rest of the work becomes targeted and effective rather than scattered.
Extract Only What You Need
The single highest-impact technique is also the simplest: stop moving data you do not need. Many pipelines do a full extraction every run, pulling every row from the source even though only a small fraction has changed. This wastes time, bandwidth, and money at every stage downstream.
Incremental extraction fixes this by pulling only new or changed records since the last run. You track a marker, such as a timestamp or an incrementing ID, and extract only rows beyond it. For sources that support it, change data capture, or CDC, goes further by streaming only the actual inserts, updates, and deletes as they happen. Switching from full to incremental loading is frequently the biggest win in any ETL process optimization effort, since it can shrink the data volume each run handles by orders of magnitude.
Beyond loading less often, extract fewer columns and filter early. Select only the columns the pipeline actually uses rather than pulling entire wide tables, and push filters as close to the source as possible so you transfer less data over the network. Every row and column you avoid moving is work that the transform and load stages never have to do. This discipline of minimizing data movement underpins nearly every other optimization technique.
Push Work to Where It Runs Best
A major theme in optimization is doing each piece of work in the place where it is cheapest and fastest. Often that means pushing transformations down into a powerful database or warehouse rather than processing rows one at a time in an external tool.
Modern data warehouses are extremely good at set-based operations across huge tables. When you let the warehouse do heavy joins, aggregations, and filtering using SQL, you take advantage of its optimized engine and parallelism. This pushdown approach usually beats pulling all the data into a separate processing layer, transforming it there, and writing it back. The less data you shuttle between systems, the faster and cheaper the pipeline runs.
This thinking is part of why many teams have shifted from traditional ETL toward ELT, where data is extracted and loaded into the warehouse first, then transformed in place. ELT leans on the warehouse’s power for the heavy lifting and avoids moving data multiple times. It is not always the right choice, since some transformations and sensitive data handling belong before loading, but for many modern stacks, transforming inside the warehouse is a significant optimization. The broader lesson holds regardless of the pattern: do the work where the data already lives whenever you can.
Parallelize and Partition
Pipelines that process everything in a single sequential stream leave most of your computing power idle. Parallelization is one of the most powerful tools in ETL process optimization, letting independent pieces of work run at the same time instead of one after another.
There are several ways to parallelize. You can split a large dataset into chunks and process them simultaneously, run independent tasks in the pipeline concurrently rather than in strict sequence, and take advantage of distributed processing frameworks that spread work across many machines. The key is identifying which steps truly depend on each other and which can run side by side, since only independent work can be parallelized safely.
Partitioning supports this and helps on its own. By organizing large tables into partitions, often by date, you let the pipeline read and write only the relevant slices instead of scanning everything. Loading a single day’s partition is far faster than rewriting an entire table, and queries that filter on the partition key skip irrelevant data entirely. Combining partitioning with parallel processing is a reliable way to make a pipeline scale, and together they form a cornerstone of serious tuning.
Make Transformations Efficient
The transformation stage is where a lot of hidden waste lives, so it rewards careful attention. The biggest gain usually comes from replacing row-by-row processing with set-based operations. Processing one record at a time is slow at scale, while operating on whole sets of data at once lets the underlying engine optimize the work.
Several habits keep transformations lean. Filter and reduce data as early as possible so later steps handle less. Write efficient joins, making sure you are joining on indexed or well-distributed keys and not accidentally creating huge intermediate results. Avoid unnecessary sorts and repeated passes over the same data. Cache or stage intermediate results that get reused rather than recomputing them. And remove transformation steps that no longer serve a purpose, since pipelines accumulate dead logic over time.
Data types matter too. Using appropriately sized types and avoiding unnecessary conversions reduces memory use and speeds processing. A transformation stage that has been carefully tuned often runs several times faster than the original, which is why this area is central to optimization even though its wins are less flashy than a big architectural change.
Tune Loading and the Target
The load stage has its own set of optimizations that are easy to overlook. Writing data into a warehouse or database can be slow when done naively, and a few adjustments make a large difference.
Use bulk loading rather than inserting rows one at a time. Most databases and warehouses offer a bulk or batch load path that is far faster than individual insert statements, sometimes by orders of magnitude. Batch your writes into sensibly sized chunks rather than tiny or enormous ones. When loading very large volumes, it can help to drop or disable indexes and constraints during the load and rebuild them afterward, since maintaining them on every row write is costly.
The target’s design affects load speed as well. Well-chosen partitioning, sort keys, and distribution keys let the warehouse write and later read data efficiently. Loading into the right partitions and clustering data the way it will be queried pays off both at load time and for every query that follows. Thoughtful target design is an underrated part of optimization, since a load stage tuned to the warehouse’s strengths removes a bottleneck that otherwise grows with your data.
Right-Size Your Resources and Costs
Performance and cost are two sides of the same coin in modern pipelines, especially in the cloud where you pay for what you use. ETL process optimization is as much about spending wisely as about raw speed.
Match your compute to the workload. Oversized clusters waste money sitting idle, while undersized ones create bottlenecks, so size resources to the actual job and scale them up or down as needed. Schedule heavy jobs for off-peak times when possible, and shut down or scale in resources when the pipeline is not running rather than paying for them around the clock. In cloud warehouses, separating storage from compute lets you pay for processing only when you actually run a job.
Cost-aware design choices add up. Storing data in efficient columnar formats reduces both storage cost and the amount of data scanned per query. Avoiding repeated full scans, reusing computed results, and pruning data you no longer need all lower the bill. Balancing speed against cost is a defining part of practical tuning.
Build in Reliability and Monitoring
A fast pipeline that fails silently is worse than a slow one that works, so reliability is part of optimization, not separate from it. Pipelines that break at three in the morning and produce wrong numbers erode trust faster than slow ones ever could.
Build in good error handling so a single bad record does not crash the whole run, and design steps to be safely re-runnable so a failed job can restart without duplicating or corrupting data. This property, often called idempotency, is what lets you recover cleanly from failures. Validate data quality as it flows through, catching problems like nulls, duplicates, and out-of-range values before they reach the warehouse and mislead everyone downstream.
Monitoring ties it all together. Track how long each run and each stage takes over time, so you can spot a pipeline slowly degrading before it becomes a crisis. Alert on failures, on runs that take far longer than usual, and on data quality checks that fail. This observability is what makes ongoing ETL process optimization possible, since you cannot improve what you cannot see. A pipeline with good monitoring tells you where the next bottleneck is forming, turning optimization from a fire drill into steady, informed maintenance.
Common Mistakes to Avoid
A few recurring mistakes undermine otherwise good pipelines. The first is optimizing without measuring, pouring effort into a stage that was never the real bottleneck. Always profile first. The second is doing full loads when incremental ones would do, which is the most common source of needless slowness and cost.
Other frequent errors include processing data row by row instead of in sets, moving data between systems more than necessary, and ignoring the target’s design so that loads and queries fight the warehouse instead of working with it. Many teams also neglect monitoring, so pipelines degrade unnoticed until they fail. And some over-engineer early, building complex distributed systems for data volumes that a simple, well-tuned pipeline would handle easily. Matching the solution to the actual scale is itself a form of optimization, since complexity has its own ongoing cost.
Frequently Asked Questions
What is the biggest single win in ETL optimization? Usually switching from full extraction to incremental or change-data-capture loading, since it can cut the data each run handles dramatically.
How do I know what to optimize first? Measure each stage separately and target the one that dominates the runtime. Optimizing anything else first wastes effort.
Is ELT better than ETL? It depends. Transforming inside a powerful warehouse often performs better and moves data less, but some transformations and sensitive data handling still belong before loading.
Does optimization mean buying more compute? Not usually. Most gains come from moving less data, processing in sets, and removing waste. Right-sizing compute matters, but throwing hardware at a poorly designed pipeline is expensive and limited.
How often should I revisit optimization? Treat it as ongoing. As data volume grows, new bottlenecks appear, so regular monitoring and periodic tuning keep a pipeline healthy over time.
Key Takeaways
- ETL process optimization makes pipelines faster, cheaper, and more reliable without changing what they produce, and it matters more as data volume grows.
- Always start by measuring each stage to find the real bottleneck, since optimizing the wrong stage wastes effort.
- The highest-impact technique is moving less data, using incremental extraction or change data capture instead of full loads, and selecting only needed columns.
- Push transformations to where the data lives, often into a powerful warehouse, which is the thinking behind the shift toward ELT in many modern stacks.
- Parallelize independent work and partition large tables so the pipeline processes and writes only the slices it needs.
- Make transformations set-based rather than row-by-row, filter early, write efficient joins, and remove dead logic to compound smaller gains.
- Speed up loading with bulk writes, sensible batch sizes, and a target whose partitioning and keys match how data is loaded and queried.
- Right-size compute, schedule and scale resources to the workload, and use efficient storage formats, since performance and cost are tightly linked in the cloud.
- Build in error handling, idempotent re-runnable steps, data quality checks, and monitoring, because reliability is part of optimization and you cannot improve what you cannot see.
- Avoid common traps like optimizing without measuring, defaulting to full loads, row-by-row processing, and over-engineering for scale you do not have.





